
Abstract
Volumetric effects such as smoke, fire, dust, and explosions are central to Visual Effects (VFX) production and are commonly represented as sparse, high-resolution VDB/OpenVDB sequences with dynamic topology. Despite rapid progress in diffusion-based 3D generation, work on sparse volumetric sequences remains difficult to compare and reproduce, due to the lack of large-scale, well organized datasets and standardized evaluation protocols. In this paper, we introduce a 1-million-sample VFX sequence of VDB dataset with standardized preprocessing, consistent metadata, and protocol-ready splits, together with a reproducible benchmark suite for both static volume generation and sequence volumes generation. We further provide an end-to-end evaluation pipeline and a scalable diffusion training framework, enabled by our Atomic-Continuous prior, which addresses the distributional mismatch between vanilla diffusion models and the intrinsic sparsity of VDB data. Our release establishes a practical infrastructure for reproducible research and systematic progress tracking in sparse volumetric sequence generation.
Contributions
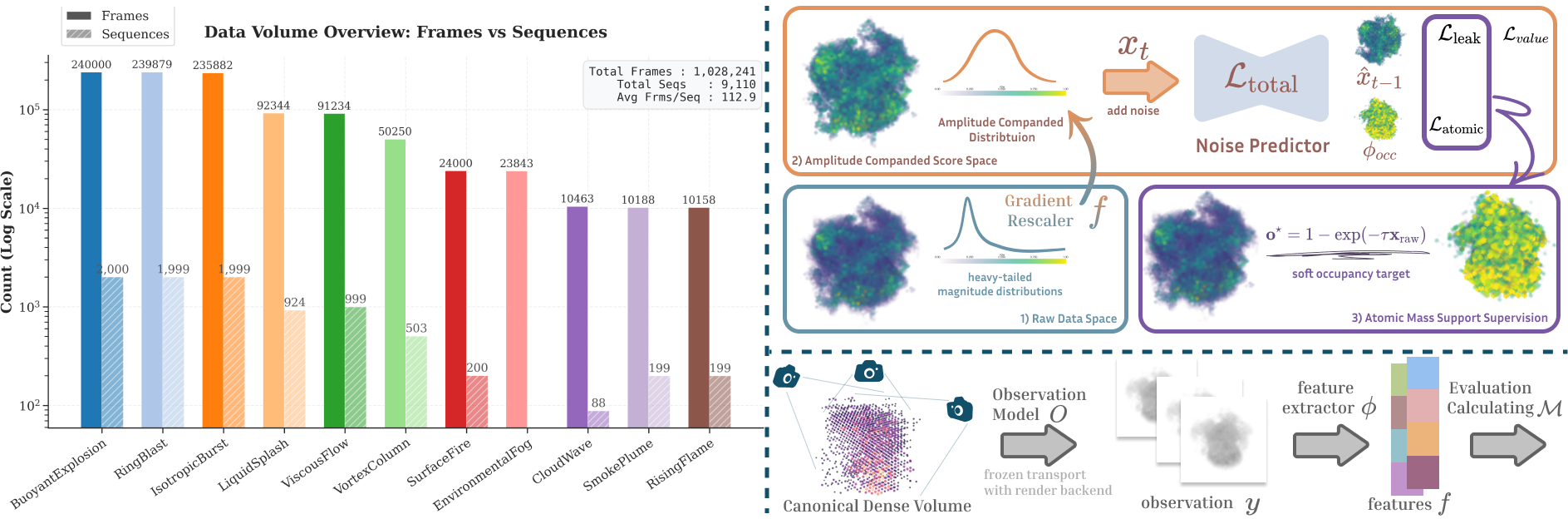
The dataset
The first million-frame collection of VFX volumes in native OpenVDB. 9,110 simulated sequences across 11 effect types, all shipped with consistent metadata and one fixed format so you can train at scale without re-cleaning the data.
The benchmark
A fixed evaluation suite for three tasks: unconditional, class-conditioned, and temporal generation. It scores visual quality and adds a structural check that catches volumes which look fine in 2D but have broken 3D shape.
The reference model
The first diffusion model trained directly on OpenVDB data. Its Atomic-Continuous prior handles the mix of empty space and heavy-tailed densities that ordinary diffusion struggles with, giving the benchmark a strong baseline.
Dataset
VfxDB is a collection of production-style VFX volumes stored as native OpenVDB grids. It doesn't introduce new simulation methods. Instead, it gives the field a clean, versioned data release and a fixed training and evaluation recipe, so different methods can be compared on equal footing and results stay reproducible over time.
Three fluid regimes
The 11 categories fall into three families that span the range of production fluids:
- Explosive & buoyant — fast expansion and rising heat (e.g. BuoyantExplosion, Ringblast).
- Dissipative & laminar — smooth motion and fine dissipation (e.g. SmokePlume, ViscousFlow).
- Environmental & chaotic — unconstrained, high-entropy fields (e.g. AtmosphericFog, IsotropicBurst).
Built from physics
Every clip is simulated in Houdini (Sparse Pyro for gases, FLIP for liquids). Each category starts from one recipe, and we sample physical controls to cover a wide range of behaviour:
- Emitters — source shape, emission rate, initial velocity.
- Solvers — buoyancy, viscosity, turbulence, dissipation.
- Forces — randomized wind and vortex confinement.
Reproducible by design
Files are shipped as raw OpenVDB with hash IDs and metadata. Every frame has a float density grid (background fixed to 0); world-space transforms and optional velocity/temperature grids are kept when available. Per-sequence manifests and version tags pin the data to a fixed snapshot, so everyone trains and evaluates against the same target.
Released under CC BY-NC 4.0 for research and benchmarking.

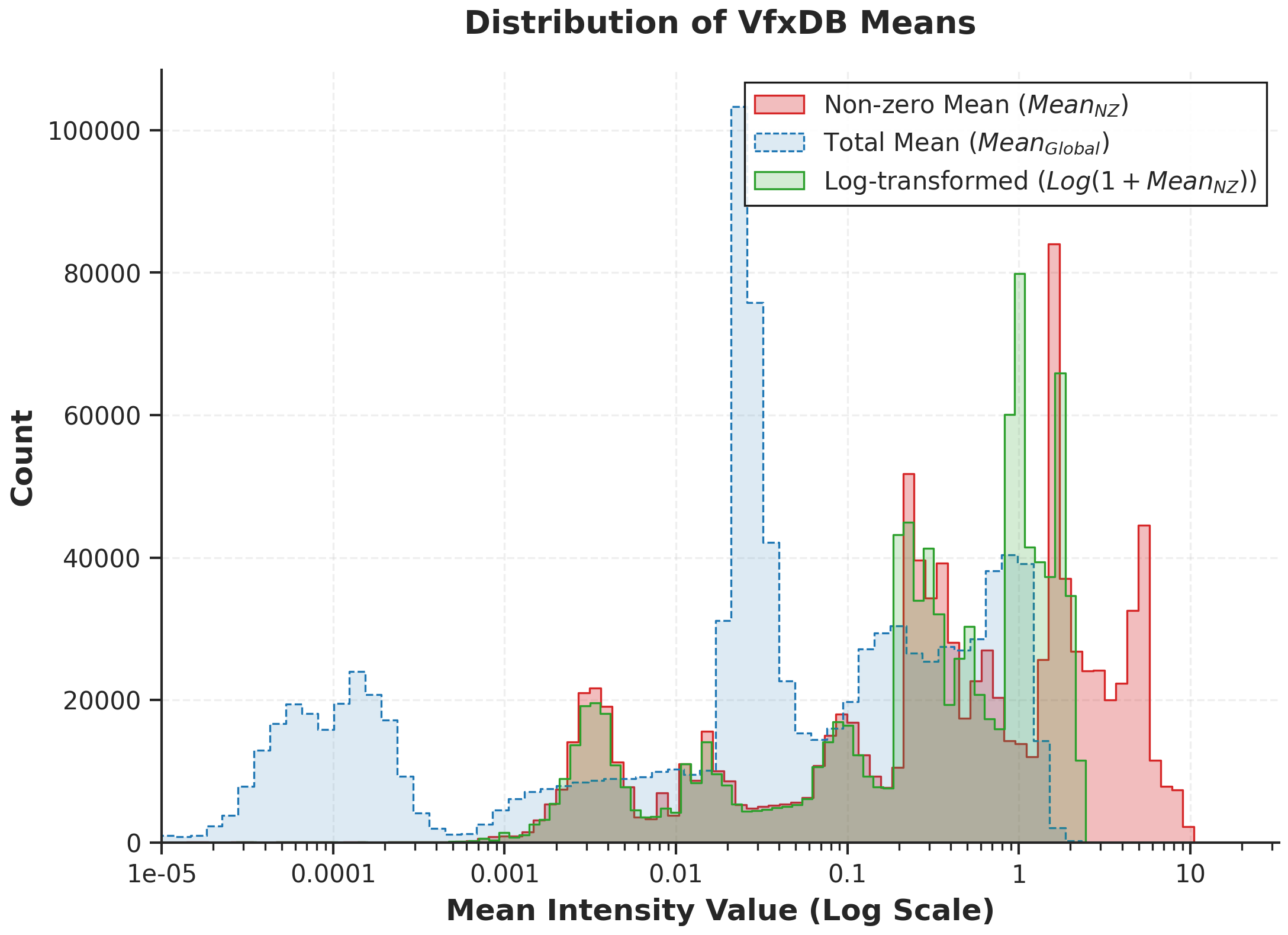
VFX volumes have a huge dynamic range. Calibrated to 32³ grids, the average over non-zero voxels sits near 1, but the average over the whole grid drops below 0.1, often to 0.01. In other words the data is sparse and heavy-tailed in both space and time — most of the volume is empty, and what isn't spans many orders of magnitude. That is exactly what makes it hard to generate.
Benchmark Protocol
The benchmark covers three generation tasks on density-only VFX volumes. Scoring is distributional: we compare a set of generated samples against a held-out reference set, not pairs of matched outputs. Every method runs through the same fixed, versioned pipeline, so results stay comparable across methods and over time.
Unconditional static
Single-frame density-volume generation with no conditioning.
Class-conditioned static
Generate a volume that matches a discrete phenomenon label.
Temporal
Generate temporally consistent volume sequences for a label.
Frozen evaluation mapping
Canonicalization brings every grid, real or generated, into the same cube at a fixed resolution (R = 128): crop to the active region, pad to a cube with empty background, and map values into [0, 1]. Observation then renders each volume from 4 fixed views at 512×512 with the same cameras and lighting for everyone. The shading deliberately exposes faint wisps instead of hiding them, so a method can't win by tuning its rendering.
Metrics
Looks right
KID on rendered views (an unbiased score that works on small VFX sets) and FVD for motion in sequences.
Holds together in 3D
Set-level MMD catches volumes that render fine from a few angles but have no coherent 3D shape underneath.
Matches the label
CLIP-Text checks that the rendered result matches the requested effect.
Method: Atomic-Continuous Priors
A VDB volume is two things at once: lots of exact zeros (empty space) and a thin shell of real density that spans a wide range of values. We write this as an Atomic-Continuous prior, p(x) = π0δ0(x) + (1−π0) pac(x). Plain Gaussian diffusion can't handle both at once: it smooths away the faint wisps and leaks density into the empty regions. Three changes fix this.
Amplitude companding
A reversible log mapping rebalances the training signal so dense cores stop dominating. It boosts the gradient on faint, low-density structures by (1 + λx̃)−1, which is what keeps thin wisps from being smoothed away.
Atomic mass supervision
Keeps empty space empty. A soft occupancy target recovers the coarse shape, and a leakage penalty pushes density to exactly zero outside the boundary, so the result stays as sparse as real VDB data.
Temporal conditioning
For sequences, the previous frame is simply stacked onto the input as an extra channel. The network learns motion from it without any heavy 4D attention, so generating a sequence costs about the same as a single frame.
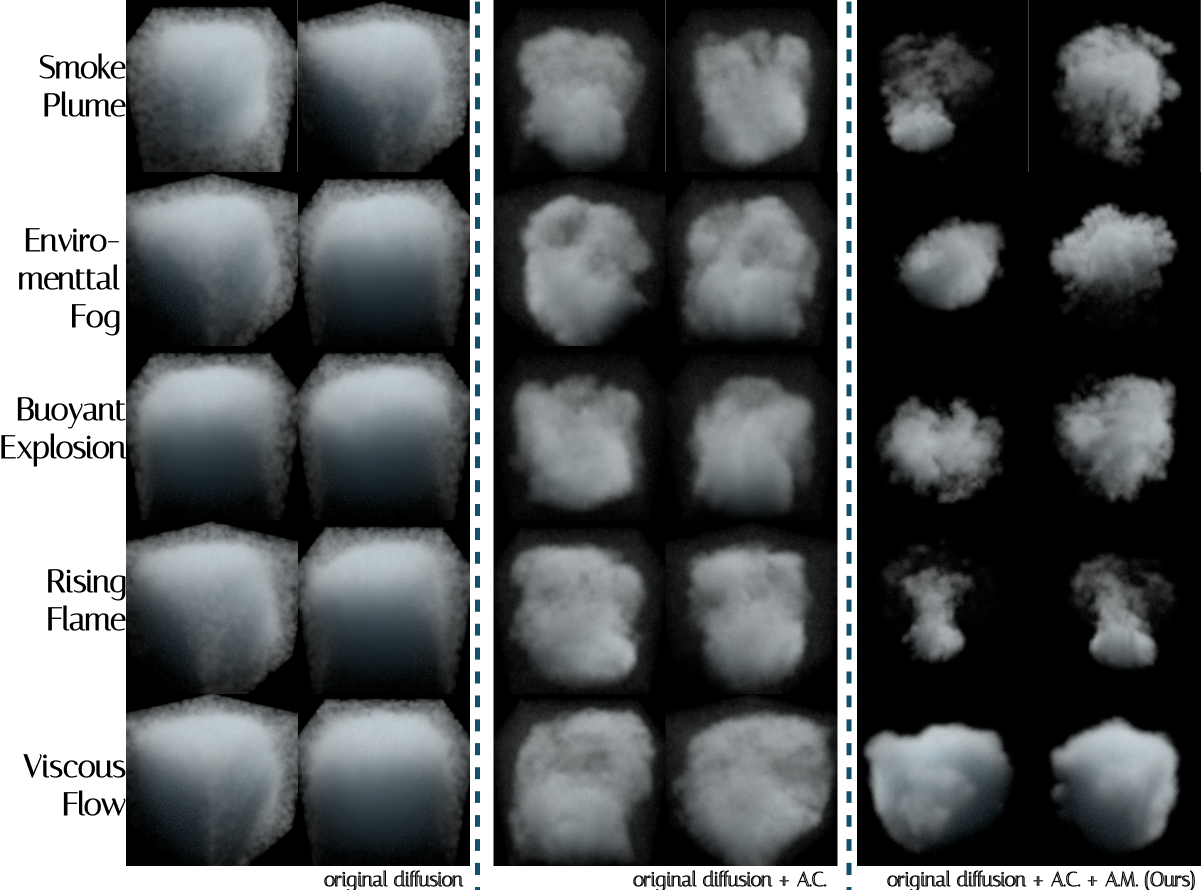
Results
Across static, temporal, and human evaluation, the reference model produces the cleanest VDB structure. The biggest gains show up exactly where it matters for VFX: 3D shape and temporal motion.

Static generation
| Method | MMD-R ↓ | MMD-G ↓ | KID ↓ | CLIP-Text ↑ |
|---|---|---|---|---|
| Baseline | 1.04 | 0.24 | 0.40 | 30.12 |
| Baseline + A.C. | 1.00 | 0.13 | 0.27 | 27.77 |
| Flux-schnell | – | – | 0.32 | 30.90 |
| Stable-Diffusion-1.5 | – | – | 0.30 | 30.14 |
| TRELLIS | 1.01 | 0.33 | 0.40 | 30.47 |
| Ours (con.) | 0.98 | 0.14 | 0.20 | 28.82 |
| Ours (con., RF) | 1.03 | 0.19 | 0.21 | 29.05 |
| Ours (unc.) | 0.96 | 0.02 | 0.13 | 27.34 |
A.C.: Amplitude Companded Score Space; con./unc.: conditional/unconditional; RF: rectified-flow variant.
Temporal generation
| Method | FVD ↓ | MMD-R ↓ | MMD-G ↓ | KID ↓ | CLIP-Text ↑ |
|---|---|---|---|---|---|
| ZeroScope | 5546 | – | – | 0.39 | 26.95 |
| ModelScope | 3333 | – | – | 0.34 | 28.73 |
| Ours (temp) | 1345 | 0.99 | 0.13 | 0.18 | 27.52 |
Human evaluation
We ran two studies with 36 professional VFX artists: one rating the quality of the dataset assets, and one ranking the generated results.
Study 1 · Dataset quality
Experts scored the ground-truth assets on a 1–5 scale (higher is better).
| Criterion | Physics | Details | Aesthetics | LOD tier |
|---|---|---|---|---|
| Mean score ↑ | 4.41 | 4.31 | 4.37 | 4.37 |
Study 2 · Generated results
Experts ranked each method's output (lower average rank is better).
| Method | Ours | Base + A.C. | TRELLIS | Baseline |
|---|---|---|---|---|
| Avg. rank ↓ | 1.47 | 2.56 | 2.73 | 3.15 |
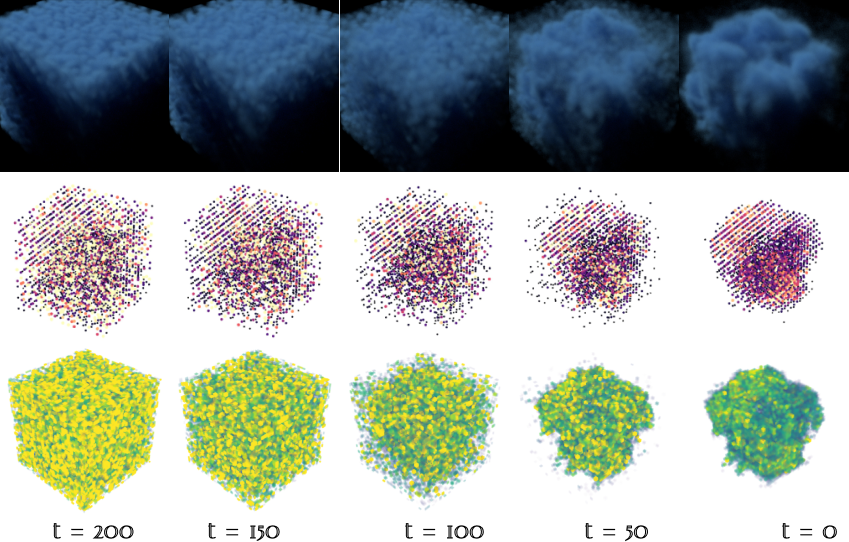
How a volume forms
Ablation
Dataset Rendered Video Previews
BibTeX
@inproceedings{shu2026vfxdb,
title = {VfxDB: A Visual Effects Volume Dataset and Benchmark for VDB-Native Generative Modeling},
author = {Shu, Junwei and Liu, Hantang and Miao, Dawei and Song, Wenzheng and
Yuan, Mingyang and Liu, Wenjie and Chen, Changgu and Li, Yang and Wang, Changbo},
booktitle = {SIGGRAPH Conference Papers '26},
year = {2026},
publisher = {Association for Computing Machinery},
doi = {10.1145/3799902.3811178},
isbn = {979-8-4007-2554-8},
url = {https://vfxdb-official.github.io/VfxDB/}
}